병렬 프로그래밍
용서하는 사람이 결국엔 더 행복해진다는 건 틀린 말이 아니다.
싱글스레드와 멀티스레드
순차적 프로그래밍 모델은 사람이 생각하는 방식과 같아서 직관적이고 자연스럽다. 대부분의 경우 한 번에 한가지씩 순서대로 처리한다. 하지만 우리가 일상 생활을 할 때, 운동을 하면서 노래를 듣고, 물을 끓이면서 감자를 깍고 노대를 듣고 효율적으로 시간을 활용한다. 여기에서 보면 동기적으로 할일과 비동기적으로 할 일 간의 적절한 균형을 찾아낸다는 것이다.
스레드는 메모리, 파일 핸들과 같이 프로세스에 할당된 자원을 공유한다. 하지만 각 스레드는 각기 별도의 프로그램 카운터, 스택, 지역 변수를 갖는다. 또한 프로그램을 스레드로 분리하면 멀티 프로세스 시스템에서 자연스럽게 하드웨어 병렬성을 이용할 수 있다. 즉 한 프로그램 내에 여러 스레드를 동시에 여러 개의 CPU에 할당해 실행시킬 수 있다.
스레드를 가벼운 프로세스라고 부르기도 하며, 현대 운영 체제의 대부분은 프로세스가 아니라 스레드를 기본 단위로 CPU 자원의 스케줄을 정한다. 스레드는 자신이 포함된 프로세스의 메모리 주소 공간을 공유하기 때문에 한 프로세스 내 모든 스레드는 같은 변수에 접근하고 힙에 객체를 할당한다.
스레드와 프로세스의 차이
-
프로그램 ( Program ) 어떤 작업을 위해 실행할 수 있는 파일
-
프로세스 ( Process ) 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램 운영 체제로 부터 시스템 자원을 할당받는 작업의 단위 동적인 개념으로 실행되는 프로그램을 의미
-
스레드 ( Thread ) 프로세스 내에서 실행되는 여러 흐름의 단위 프로세스의 특정한 수행 경로 프로세스가 할당받은 자원을 이용하는 실행의 단위
스레드에 대해서
- 쓰레드가 프로세스보다 컨텍스트 스위칭이 빠른 이유
쓰레드가 프로세스보다 컨텍스트 스위칭이 빠른 이유는 메모리 영역을 공유하기 때문이다.
쓰레드는 해당 쓰레드를 위한 스택을 생성할 뿐, 그 이외의 Code, Data, Heap 영역을 공유한다. Stack을 독립적으로 할당하는 이유는 스택은 함수 호출 시 전달되는 인자. 되돌아갈 주소값 및 함수 내에서 선언하는 변수 등을 저장하기 위해 사용되는 메모리 공간이다. 따라서 스택 메모리 공간이 독립적이라는 것은 독립적인 함수 호출이 가능하다는 것이고, 이는 독립적인 실행흐름이 추가되는 것이다. 결과적으로 실행 흐름의 추가를 위한 최소 조건이 독립된 스택을 제공하는 것이다.
스레드 안정성의 기본
스레드 안정성은 생각보다 미묘하기도 하다. 동기화를 충분히 해두지 않으면 여러 스레드에서 실행되는 연산의 순서가 때론 놀라운 만큼 예측하기가 어렵다.
// 스레드가 하나일 하나일 때는 아래의 코드는 아무런 문제가 없다. 하지만 스레드가 여럿일 때는 제대로 동작하지 않는다.
@NotThreadSafe
public class UnsafeSequence {
private int Value;
/** 유일한 값을 리턴 */
public int getNext(){
return value++;
}
}
- UnsafeSequence의 문제는 타이밍이 좋지 않은 시점에 두 개의 스레드가 getNext 메소드를 동시에 호출햇을 때 같은 값을 얻을 가능성이 있다.
- 만약 @ThreadSafe 라고 표시하면 클래스를 사용하는 사람은 멀티스레드 환경에서 문제가 없다는 점을 명확히 할 수 있고, 유지보수하는 개발자는 스레드 안정성이 계속 보장돼야 한다는 점을 주의할 수 있다.
- UnsafeSequence 는 경쟁조건이라고 하는 흔한 위험성을 보여주는 좋은 예제다.
경쟁조건
병행 프로세스의 자원 경쟁
병행 프로그램에서 프로세스가 두개 이상의 동작을 동시에 수행하려고 할 때 발생하는 비정상적인 상태
스레드 안정성을 대한 이해
스레드는 서로 같은 메모리 주소 공간을 공유하고 동시에 실행되기 때문에 다른 스레드가 사용중일지도 모르는 변수를 알거나 수정할 수도 있다. 이는 상당히 편리한데, 다른 스레드 간 통신 방식보다 데이터 공유가 훨씬 쉽기 때문이다. 하지만 이점은 위험 요소이기도 한다. 즉 데이터가 예측 못한 시점에 변경돼 스레드가 혼동될 수도 있다. 여러 스레드가 같은 변수를 읽고 수정하게 되면 원래 순차적이던 프로그래밍 모델에 비순차적인 요소가 들어가 혼란스럽고 동작과정을 추론하기 어려워질 수도 있다. 멀티스레드 프로그램이 동작하는 모들을 예측하려면 스레드가 서로 간섭하지 않도록 공유된 변수에 접근하는 시점에 적절하게 조율해야한다. 다행히 자바에서는 공유 변수 접근을 조율하기 위한 동기화 수단이 제공된다.
@ThreadSafe
public class Sequence {
@GuardedBy("this") private int value;
public synchronized int getNext(){
return value;
}
}
동시 수행 코드를 개발할 때는 반드시 스레드 안전성 문제를 신경 써야 한다.
성능위험
잘 설계된 병렬 프로그램은 스레드를 사용해서 궁극적으로 성능을 향상시킬수 있다. 하지만 스레드를 사용하면 실행 중에 어느정도 부하가 생기는 것도 사실이다. 스레드가 많은 프로그램에서는 컨텍스트 스위칭(다른 스레드가 실행 될 수 있게 스케줄러가 현재 실행 중인 스레드를 잠시 멈출 때)이 더 빈번하고, 그 때문에 상당한 부담이 생긴다. 즉, 실행 중인 컨텍스트를 저장하고 다시 읽어 들여야 하며, 메모리를 읽고 쓰는 데 있어 지역성이 손실되고, 스레드를 실행하기도 버거운 CPU 시간을 스케쥴링하는데 소모해야한다. 또 스레드가 데이터를 공유할 때는 동기화 수단도 사용해야한다. 이런 동기화는 컴파일러 최적화를 방해하고, 메모리 캐시를 지우거나 무효화 하기도 한다.
- 컨텍스트 스위칭
한 프로세스가 CPU를 사용중 일 때 다른 프로세스가 CPU를 사용하기 위해, 이전의 프로세스 상태를 보관하고 새로운 프로세스 상태를 CPU에 적재하는 것을 말한다. 컨텍스트 스위칭이 발생할 때마다 오버헤드가 발생해 작업을 수행할 수 없다. Process가 추가되면 Data, Heap, Stack 모든 것이 그대로 추가 된다. Process 끼리는 데이터 공유가 불가능하다.
- 스레드 컨텍스트 스위칭
OS는 스레드 하나의 작업을 진행하기 위해 해당 스레드의 Context를 읽어오고, 다시 다른 스레드로 작업을 변경할 때, 이전 스레드의 Context를 저장하고 작업을 진행할 스레드의 Context를 저장하고 작업을 진행할 스레디의 Context를 읽어오는 작업을 말한다. Data와 Heap은 그대로 사용되어 공유하게 되고, Stack 만 추가되어 새로운 class 호출이 용이하다. 즉 하나의 프로그램에서 동시에 두 개 이상의 일을 수행할 필요가 있으면 스레드를 이용하면 된다.
스레드 안정성
공유되고 변경할 수 있는 상태에 대한 접근을 관리하는 것
공유 되었다는 것은 여러 스레드가 특정 변수에 접근할 수 있다는 뜻이고, 변경할수 있다는 것은 해당 변수 값이 변경될 수 있다는 뜻이다. 스레드 안정성 이 마치 코드를 보호하는 것처럼 이해하는 경우가 많지만, 실제로는 데이터에 제어없이 동시에 접근하는 것을 막으려는 의미임을 알아두자.
스레드가 하나 이상이 상태 변수에 접근하고 그 중 하나라도 변수에 값을 쓰면, 해당 변수를 접근할 때 관련된 모든 스레드가 동기화를 통해 조율해야한다. 자바에서 동기화를 위한 기본 수단은 synchronized 키워드로서 배타적인 락을 통해 보호 기능을 제공한다. 하지만 volatile 변수, 명시적 락, 단일 연산 변수(atomic variable)를 사용하는 경우에도 ‘동기화’ 라는 용어를 사용한다.
동기화를 처리할 수 있는 3가지 방식
만약 여러 스레드가 변경할 수 있는 하나의 상태 변수를 적절한 동기화 없이 접근하면 그 프로그램은 잘못된 것이다.
이렇게 잘못된 프로그램을 고치는 데는 세가지 방법이 있다.
- 해당 상태 변수를 스레드 간에 공유되지 않거나
- 해당 상태 변수를 변경할 수 없도록 만들거나
- 해당 상태 변수에 접근할 때는 언제나 동기화
스레드 안전한 클래스를 설계할 땐, 바람직한 객체 지향 기법이 왕도다. 캡슐화와 불변객체를 잘 활용하고, 불변 조건을 명확하게 기술해야 한다.
여러 스레드가 클래스에 접근할 때, 실행 환경이 해당 스레드들의 실행을 어떻게 스케쥴하든 어디에 끼워 넣든, 호출하는 쪽에서 추가적인 동기화나 다른 조율 없이도 정확하게 동작하면 해당 클래스는 스레드 안전하다고 말한다.
애당초 단일 스레드 환경에서도 제대로 동작하지 않으면 스레드 안전할 수 없다. 객체가 제대로 구현됬으면 어떤 일련의 작업도 해당 객체의 불변 조건이나 후조건에 위배될 수 없다.
스레드 안전한 클래스는 클라이언트 쪽에서 별도로 동기화할 필요가 없도록 동기화 기능도 캡슐화 한다.
- 상태 없는 객체는 항상 스레드 안전하다.
// 상태가 없는 항상 안전한 객체
// 상태 없는 객체에 접근하는 스레드가 어떤 일을 하든 다른 스레드가 수행하는 동작의 정확성에 영향을 끼칠 수 없기 때문에 객체는 항상 스레드에 안전하다.
@ThreadSafe
public class StatelessFactorizer implements Servlet {
public void service(ServletRequest req, SevletRespones resp){
BigInteger i = extractFromRequest(req);
BigInteger[] factors = factor(i);
encodeIntoResponse(resp, factors);
}
}
경쟁 조건
경쟁조건은 상대적인 시점이나 또는 JVM이 여러 스레드를 교차해서 실행하는 상황에 따라 계산의 정확성이 달라질 때 나타난다. 다시 말하자면 타이밍이 딱 맞았을 때만 정답을 얻는 경우를 말한다.
경쟁 조건 vs 데이터 경쟁
데이터 경쟁은 공유된 final이 아닌 필드에 대한 접근을 동기화로 보호하지 않았을 때 발생한다. 스레드가 다음에 다른 스레드가 읽을 수 있는 변수에 값을 쓰거나 다른 스레드가 마지막에 수정했을 수 있는 변수를 읽을 때 두 스레드 모두 동기화하지 않으면 데이터 경쟁이 생길 위험이 있다. 데이터 경쟁이 있는 코드는 자바 메모리 모델 하에선 유용한 정의된 의미가 없다. 모든 경쟁조건이 데이터 경쟁인 것 아니고, 모든 데이터 경쟁이 경쟁 조건인 것도 아니다. 하지만 경쟁조건이든 데이터 경쟁이든 병렬 프로그램을 예측할 수 없이 실패하게 만든다.
@NotThreadSafe
public class LazyInitRate {
private ExpensiveObject instance = null;
public ExpensiveObject getInstance() {
if(instance == null){
instance = new ExpensiveObject();
}
return instance;
}
}
경쟁조건으로 인하여 제대로 동작하지 않는 경우
instance 라는 변수가 null이라는 사실을 본 다음 스레드 A는 ExpensiveObject 의 인스턴스를 새로 생성한다. 스레드 B도 instance 변수가 null 인지 살펴본다. 이때 instance 가 null의 여부는 스케줄이 어떻게 변경될지 또는 스레드 A가 ExpensiveObject 인스턴스를 생성하고 instance 변수에 저장하기 까지 얼마나 걸리는지 등의 예측하기 어려운 타이밍에 따라 달라진다. 원래 getInstance는 항상 같은 인스턴스를 리턴하도록 설계돼 있는데, 스레드 B가 살펴보는 그 시점에 instance가 null이면 getInstance를 호출한 두 스레드가 각각 서로 다른 인스턴스를 가져갈 수 도 있다.
가시성
메모리 상의 공유된 변수를 여러 스레드에서 서로 사용할 수 있게 하려먼 반드시 동기화 기능을 구현해야 한다. 공유 자원(변수)에 대해서는 반드시 적절한 동기화 작업이 필요하다.
동기화 기능을 지정하지 않으면 컴파일러나 프로세서, JVM(자바 가상 머신) 등이 프로그램 코드가 실행되는 순서를 임의로 바꿔 실행하는 이상한 경우가 발생하기도 한다. 다시 말하자면, 동기화 되지 않은 상황에서 메모리 상의 변수를 대상으로 작성해둔 코드가 ‘반드시 이런 순서로 동작할 것이다’ 라고 단정 지을 수 없다.
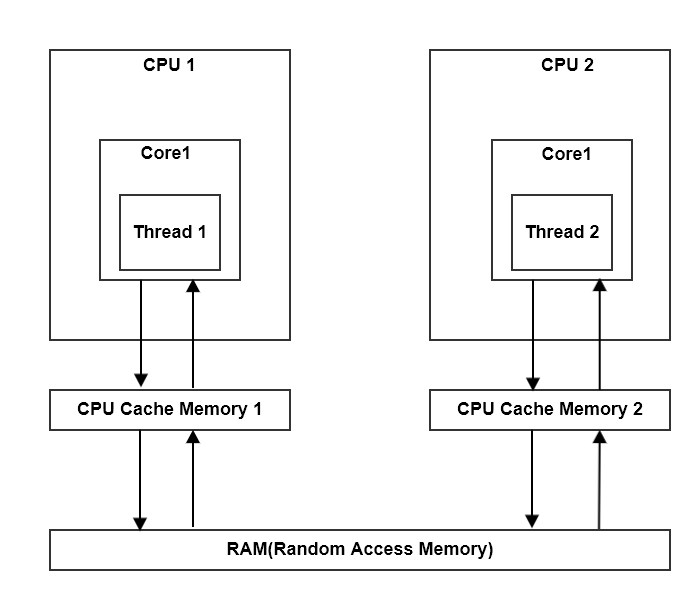
Java의 메모리 모델을 공부하다 보면 그 중요 위치에 메모리 가시성과 메모리 장벽이라는 것이 등장한다. 비단 Java의 메모리 모델에서 뿐만 아니라 Concurrent Programming에서도 주요 고려사항으로 이 메모리 가시성과 메모리 장벽이 언급된다.
-
메모리 가시성(Memory Visibility) 우선 Concurrent Programming , Parallel Programming과 관련하여 메모리 가시성(Memory Visibility)라는 것을 간단히 정리하면, 한 Thread에서 변경한 특정 메모리의 값이, 다른 Thread에서 제대로 읽어지는지가 라고 할 수 있다. 그런데 이 메모리 가시성이 중요한 이슈가 되는 경우는 다중 CPU, 다중 코어에서다. Thread가 여러 코어(CPU)에서 동시에 실행되는 상황에서 이 메모리 가시성은 중요한 고려 사항이 된다. 다중 코어(CPU)에서 메모리 가시성 문제가 발생하는 첫번째 이유는, 앞선 글에서도 언급했지만 CPU의 메모리 아키텍처, 즉 레지스터와 캐쉬의 존재 때문이다. 각각의 코어(CPU)는 메인 메모리와 별도로 각각의 레지스터와 캐쉬를 가지기 때문이다. 다중 코어(CPU)에서 메모리 가시성 문제가 발생하는 두번째 이유는, 컴파일러 최적화 때문이다. 컴파일러는 프로그램이 최대한 빠르게 실행될 수 있도록 코어(CPU)의 레지스터와 캐쉬를 사용하도록 최적화 하기 때문인 것이다. 결국 Shared Memory 모델의 Concurrent, Parallerl Programming 에서는, 한 코어(CPU)에서의 값 변경을 여러 코어(CPU)가 공유하는 메인 메모리로 반영하는 작업을 적절히 수행해야 메모리 가시성을 유지할 수 있게 된다. 익히 알고 있겠지만 코어(CPU)의 레지스터나 캐쉬의 값을 메인 메모리로 반영하는 것은 느리다. 하지만 꼭 필요하다. 따라서 결론은 적절히 필요한 시점에만 메인 메모리로 반영하도록 하는 것이 필요하다. 그래서 등장하는 개념이 바로 메모리 장벽(Memory Barrier)이다.
-
메모리 장벽( Memory Barrier )
이 메모리 장벽(Memory Barrier)은 Memory Fence라고도 하는데 간단히 정리하면, 이 메모리 장벽을 만나기 전, 그전까지 코어(CPU)의 레지스터나 캐쉬값의 변경을 메인 메모리에 반영하는 것이라고 할 수 있다. 이를 메인 메모리로 Flush 한다고도 하는데, 이렇게 함으로써 다른 코어(CPU)에서 변경된 값을 읽을 수 있도록 하는 것이다. 이 메모리 장벽을 사용하려면 결국 컴파일러가 어떤 식으로든 메모리 장벽을 설치하도록 지시해야 하는데, 일반적으로 동기화를 위한 Lock 을 사용하는 곳에는 암시적으로 메모리 장벽이 설치된다. Lock 이라는 것도 결국 Lock을 소유하는 코어(Core)가 특정 메모리에 표시를 해 두면, 다른 코어(CPU)가 그 값을 보고 자신이 Lock를 소유할 수 없는 상태라는 것을 판단해야 하기 때문에, 이 Lock을 위한 메모리를 쓰고 읽는 과정에서 메모리 장벽이 필수적으로 들어가야 한다. Java를 예로 들면, synchronized 블록의 진입과 탈출 시에는 메모리 장벽을 거치게 되는 것이다. 전문가들이 Thread간에 공유되는 데이터를 읽고 쓰는 경우에는 항상 synchronized 블록으로 묶어 주라고 하는 이유도 바로 여기에 있다.
이 메모리 가시성과 메모리 장벽과 관련하여 C, C++,Java 같은 언어에서 최근에 등장하는 Atomic~~~로 표현되는 라이브러리들이 있는데, 사실 나는 처음에는 Java의 AtomicInteger같은 것이 필요한 이유를 알 수 없었다. 32bit 기반의 CPU에서 int 값을 읽고 쓰는 것은 동기화가 필요 없이 원자적으로(atomic)하게 실행되기 때문에 이를 위해 AtomicInteger라는 클래스를 따로 만들 이유가 없어보였다.(물론 이 AtomicInteger는 incrementAndGet() 같은 편이 메소드가 있지만 이 메소드를 사용하지 않더라도 AtomicInteger를 사용해야 하는 상황을 이야기 하는 것이다. )
하지만 이 Atomic~를 사용해야 하는 제일 중요한 이유는 메모리 가시성 때문이다. 이 Atomic~에 값을 쓰거나 읽는 것은 레지스터나 캐쉬가 아니라 바로 메인 메모리에서 수행되도록 해주는 것이다. 따라서 무거운 synchronized 블록으로 변수를 묶지 않고도, 메모리 가시성을 확보할 수 있게 된다. (Java에선는 volatile도 이 Atomic~와 같은 역할을 한다고 할 수 있지만, 이 volatile은 예전부터 여러 Java 구현체(implementor)에서 그 기능이 명확하지 않아 혼란을 초래했기 때문에 Atomic~을 새로 만든 것 같다. )
메모리 장벽은 재배치(reordering)과 관련한 내용도 있다. 요지는, 컴파일러는 메모리 장벽을 넘어서까지 재배치를 하지는 않는다는 것이다. 이 역시도 생각해보면, 메모리 장벽은 이전 까지 메모리 작업을 메인 메모리로 반영하는 것인데, 이때 그 메모리 장벽 이전까지라는 것은 프로그래머가 코드에 표현한 순서로 메모리 장벽 이전까지가 된다. 따라서 컴파일러는 이 메모리 장벽을 넘어서는 재배치(reordering)은 하지 않게 되는 것이다.
복합 동작
작업 A를 실행 중인 스레드 관점에서 다른 스레드가 작업 B 를 실행할 때 작업 B 가 모두 수행됐거나 또는 전혀 수행되지 않는 두가지 상태로만 파악된다면 작업 A의 눈으로 볼 때 작업 B는 단일 연산이다. 단일 연산 작업은 자신을 포함해 같은 상태를 다루는 모든 작업이 단일 연산인 작업을 지칭한다.
@ThreadSafe
public class CountingFactorizer implements Servlet {
private final AtomicLong count = new AtomicLong(0);
public long getCount() { return count.get() }
public void service(ServletRequest request, ServletResponse response){
BigInteger i = extractFromRequest(req);
BigIntegerp[] factors = factor(i);
count.incrementAndGet();
encodeIntoResponse(resp, factors);
}
}
단일 연산
a = b ++; 를 봤을 때 동기화가 안되어 있다면 b를 증가하는 연산(a++)과 a에 대입하는 연산(a=…)이 두 개가 있으므로 단일 연산으로 볼 수 없다. 해당 연산이 동기화 되었다면 외부에서 성공과 실패로 나뉘므로 단일 연산이다.
가능하면 클래스 상태를 관리하기 위해 AtomicLog 처럼 스레드에 안전하게 이미 만들어져 있는 객체를 사용하는 편이 좋다. 스레드 안전하지 않는 상태 변수를 선언해두고 사용하는 것보다 이미 스레드 안전하게 만들어진 클래스가 가질 수 있는 가능한 상태의 변화를 파악하는 편이 휠씬 쉽고, 스레드 안전성을 더 쉽게 유지하고 검증할 수 있다.
원자성이란
CPU가 처리하는 하나의 단일 연산을 의미한다. 하나의 Thread에서 읽기와 쓰기, 다른 Thread에서는 읽기만 한다면, 원자성을 고려한 변수를 선언하고 싶은 경우, volatile 변수를 활용한다. ( 메모리 문제 고려해야함 )
Volatile 변수는 약간 다른 형태의 좀더 약한 동기화 기능을 제공하는데, 다시 말해 volatile로 선언된 변수의 값을 바꿨을 때 다른 스레드에서 항상 최신 값을 읽어갈 수 있도록 해준다. 특정 변수를 선언할 때 volatile 키워드를 지정하면 컴파일러와 런타임 모두 ‘이 변수는 공유해 사용하고, 따라서 실행 순서를 재배치해서는 안된다’라고 이해한다. volatile로 지정된 변수는 프로세스의 레지스터에 캐시 되지도 않고, 프로세서의 외부 캐시에도 들어가지 않기 때문에 volatile 변수의 값을 읽으면 항상 다른 스레드가 보관해둔 최신의 값을 읽어갈 수 있다.
동기화하고자 하는 부분을 명확하게 볼 수 있고, 구현하기가 훨씬 간단한 경우에만 volatile 변수를 활용하자. 반대로 작은 부분이라도 가시성을 추론해봐야하는 경우에는 volatile 변수를 사용하지 않는 것이 좋다. volatile 변수를 사용하는 적절한 경우는, 일반적으로 변수에 보관된 클래스의 상태에 대한 가시성을 확보하거나 중요한 이벤트가 발생했다는 등의 정보를 정확하게 전달하고자 하는 경우 등이 해당된다.
락을 사용하면 가시성과 연산의 단일성을 모두 보장받을 수 있다. 하지만 volatile 변수는 연산의 단일성은 보장하지 못하고 가시성만 보장한다.
volatile 변수를 사용할 수 있는 케이스
- 변수에 값을 저장하는 작업이 해당 변수의 현재 값과 관련이 없거나 해당 변수의 값을 변경하는 스레드가 하나만 존재
- 해당 변수가 객체의 불변조건을 이루는 다른 변수와 달리 불변조건에 관련되어 있지 않다.
- 해당 변수를 사용하는 동안에는 어떤 경우라도 락을 걸어 둘 필요가 없는 경우
Java volatile
- volatile keyword는 Java 변수를 Main Memory에 저장하겠다라는 것을 명시하는 것입니다.
- 매번 변수의 값을 Read 할때 마다 CPU Cache 에 저장된 값이 아닌 Main Memory 에서 읽는 것입니다.
- 변수의 값을 write 할 때 마다 Main Memory에 까지 작성하는 것입니다.
- Multi Thread 환경에서 하나의 Thread만 read & write 하고 나머지 Thread가 read 하는 상황에서 가장 최신의 값을 보장합니다.
만약에 Multi Thread 환경에서 Thread가 변수 값을 읽어올 때 각각의 CPU Cache에 저장된 값이 다르기 때문에 변수 값 불일치 문제가 발생하게 됩니다.
volatile를 사용하기 적합할 때
MultiThread 환경에서 하나의 Thread만 Read&Write를 하고 나머지 Thread가 read 하는 상황에서 가장 최신의 값을 보장합니다. 하지만 하나의 Thread에서만 write하더라도, 그 변수(메모리)에 대한 접근과 수정이 잦다면 다른 스레드에서 read할때 원자성이 보장되지 않을 것 같습니다.
volatile를 사용하기 부적합할 때 하나의 Thread가 아닌 여러 Thread에서 write를 하는 상황에서는 적합하지 않습니다. 이와 같은 경우에는 synchronized를 통해서 read & write의 원자성을 보장해야 합니다.
volatile의 성능 영향
volatile은 변수의 read와 write를 Main Memory에서 진행하게 됩니다.
CPU Cache 보다 Main Memory가 비용이 더 크기 때문에 변수 값 일치를 보장해야 하는 경우에만 volatile를 사용하는 것이 좋습니다.
@ThreadSafe
public class VolatileCachedFactorizer implements Servlet {
private volatile OneValueCache cache = new OneValueCache(null, null);
public void service(ServletRequest req, ServletResponse resp){
BigInteger i = extractFromRequest(req);
BigInteger[] factors = cache.getFactors(i);
if( factors == null ) {
factors = factor(i);
cache = new OneValueCache(i, factors);
}
encodeIntoResponse(resp, factors);
}
}
스레드 안정성의 정의
스레드 안정성의 정의에 따르면 여러 스레드에서 수행되는 작업의 타이밍이나 스케줄링에 따른 교차 실행과 관계 없이 불변 조건이 유지돼야 스레드 안전하다.
상태를 일관성 있게 유지하려면 관련 있는 변수들을 하나의 단일 연산으로 갱신해야 한다.
자바에는 단일 연산 특성을 보장하기 위해 Synchronized 라는 구문으로 사용할 수 있는 락을 제공한다. 모든 자바 객체는 락으로 사용할 수 있다.
스레드가 하나 이상 상태 변수에 접근하고 그 중 하나라도 변수에 값을 쓰면 변수에 접근할 때 관련된 모든 스레드가 동기화를 통해 조율해야한다.
// 이와 같이 자바에 내장된 락을 암묵적인 락 혹은 모니터 락이라고 한다.
synchronized (lock) {
// lock으로 보호된 공유 상태에 접근하거나 해당 상태를 수정한다.
}
암묵적인 락은 뮤텍스로 동작한다. 즉 한 번에 한 스레드만 특정 락을 소유할 수 있다. 스레드 B가 가지고 있는 락을 스레드 A가 얻으려면, A는 B가 해당 락을 놓을 때까지 기다려야 한다.
교착 상태(Deadlock) 발생 조건
- 상호배제 ( Mutual Exclusion ) 한 자원에 대한 여러 프로세시의 동시 접근 불가
- 점유와 대기 ( Hold And Wait ) 자원을 가지고 있는 상태에서 다른 프로세스가 사용하고 있는 자원의 반납을 기다리는 것
- 비선점 ( Non Preemptive ) 다른 프로세스의 자원을 강제로 가져올 수 없음
- 환형대기 ( Circle wait ) 각 프로세스가 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있는 것
재인입성 ( Reentrancy - 재진입 가능성 )
스레드가 다른 스레드가 가진 락을 요청하면 해당 스레드는 대기 상태에 들어간다. 하지만 암묵적인 락은 재진입 가능하기 때문에 특정 스레드가 자기가 이미 획득한 락을 다시 확보할 수 있다. 재진입성은 확보 요청의 단위가 아닌 스레드 단위로 락을 얻는다는 것을 의미한다.
public class Reentrancy {
public synchronized void getA(){
System.out.println("a");
// b 가 synchronized 로 선언되어 있지만 a 진입시 이미 락을 획득하였으므로, b를 호출할 수 있다.
b();
}
public synchronized void b(){
System.out.println("b");
}
public static void main(String[] args){
new Reentrancy().a();
}
}
reentrant 함수는 재귀호출을 포함한 병렬 실행을 보장하는 코드를 의미합니다. 즉 쓰레드에서도 마음껏 사용해서 병렬적으로 실행되도 작동되고, 자신이 재귀호출이 되어도 안전하다는 뜻입니다.
컴퓨터 프로그램 또는 서브 루틴에 재진입성이 있으면, 이 서브 루틴은 동시에(병렬) 안전하게 실행 가능하다. 즉 재진입이 가능한 루틴은 동시에 접근해도 언제나 같은 실행결과를 보장한다. 재진입이 가능하려면 함수는 다음 조건을 만족해야 한다.
- 정적 (전역) 변수를 사용하면 안된다.
- 정적 (전역) 변수의 주소를 반환하면 안된다.
- 호출자가 호출시 제공한 매개변수만으로 동작해야한다.
- 싱글턴 객체의 잠금에 의존하면 안된다.
- 다른 비-재진입 함수를 호출하면 안된다.
락으로 상태 보호하기
여러 스레드에서 접근할 수 있고 변경 가능한 모든 변수를 대상으로 해당 변수에 접근할 때는 항상 동일한 락을 먼저 확보한 상태여야 한다. 이 경우 해당 변수는 확보된 락에 의해 보호된다고 말한다.
모든 변경할 수 있는 공유 변수는 정확하게 단 하나의 락으로 보호해야한다. 유지보수 하는 사람이 알 수 있게 어느 락으로 보호하고 있는지를 명확하게 표시하라.
락을 활용함에 있어 일반적인 사용 예는 먼저 모든 변경 가능한 변수를 객체 안에 캡슐화 하고, 해당 객체의 암묵적인 락을 사용해 캡슐화한 변수에 접근하는 모든 코드 경로를 동기화 함으로써 여러스레드가 동시에 접근하는 상태에서 내부 변수를 보호하는 방법이다.
public class TestLockProtect {
private Lock lockForProtect = new Lock();
private String targetValue = "";
public String getTargetValue(){
synchronized(this){
targetValue = "Value";
return targetValue;
}
}
}
public class TestLockProtect {
private Lock lockForProtect = new Lock();
private String targetValue = "";
public String getTargetValue(){
lockForProtect.lock();
targetValue = "Value";
lockForProtect.unlock();
return targetValue;
}
}
public class Lock {
private boolean isLocked = false;
public synchronized void lock() {
throws InterruptedException{
while(isLocked){
wait();
}
isLocked = true;
}
public synchronized void unlock(){
isLocked = false;
notify();
}
}
}
// synchronized의 경우 내부 함수의 synchronized에 진입이 가능하다. 그 이유는 'this' 에 대한 동기화를 의미하기 때문이다.
// 하지만 Lock에 대해서는 내부 함수 내의 lock에 대해서는 재진입이 불가능하다.
활동성과 성능
동기화된 인수 분해 서블릿에 여러 요청이 들어왔을 때 어떤 일이 생기는지 봣을 때 이것들은 요청이 큐에 쌓이고 순서대로 하나씩 처리된다. 이런 방법으로 동작하는 웹 애플리케이션은 변경 처리 능력이 떨어진다고 말한다. 처리할 수 있는 동시 요청의 개수가 자원의 많고 적음이 아닌 애플리케이션 자체의 구조때문에 제약된다. 다행이 synchronized 블록의 범위를 줄이면 스레드 안전성을 유지하면서 쉽게 동시성을 향상 시킬 수 있다. 이때 synchronized 블록의 범위를 너무 작게 줄이지 않도록 조심해야한다. 다시 말해 단일 연산으로 처리해야하는 작업을 여러 개의 synchronized 블록으로 나누진 말아야 한다.
@ThreadSafe
public class CachedFactorizer implements Servlet {
@GuardedBy("this") private BigInteger lastNumber;
@GuardedBy("this") private BigInteger[] lastFactors;
@GuardedBy("this") private long hits;
@GuardedBy("this") private long cacheHits;
public synchronized long getHits() { return hits; }
public synchronized double getCacheHitRadio() {
return ( double ) cacheHits / (double) hits;
}
public void service(ServletRequest req, ServletResponse resp){
BigInteger i = extractFromRequest(req);
BigInteger[] factors = null;
synchronized(this){
++ hits;
if(i.equals(lastNumber)){
++ cacheHits;
factors = lastFactors.clone();
}
}
if(factors == null){
factors = factor(i);
synchronized (this) {
lastNumber = i;
lastFactors = factors.clone();
}
}
encodeIntoResponse(rest, factors);
}
}
종종 단순성과 성능이 서로 상충할 때가 있다. 동기화 정책을 구현할 때는 성능을 위해 조급하게 단순성을 희생하고픈 유혹을 버려야한다.
복잡하고 오래 걸리는 계산 작업, 네트웍 작업, 사용자 입출력 작업과 같이 빨리 끝나지 않을 수 있는 작업을 하는 부분에서는 가능한 한 락을 잡지말아라.
스테일 데이터
제대로 동기화 되지 않은 프로그램을 실행 했을 때 나타날 수 있는 여러 종류의 어이없는 상황 가운데 스테일 데이터라는 결과를 체험했다.

단일하지 않는 64비트 연산
64비트를 사용하는 숫자형에 volatile 키워드를 사용하지 않는 경우에는 난데 없는 값마저 생길 가능성이 있다. 자바 메모리 모델은 메모리에서 값을 가져오고 fetch 저장 store 하는 연산이 단일해야 한다고 정의하고 있지만, volatile로 지정하는 않은 long이나 double형의 64비트 값에 대해서 메모리에 쓰거나 읽을 때 두 번의 32비트 연산을 사용할 수 있도록 허용하고 있다.
락과 가시성
내장된 락을 적절히 활용하면 특정 스레드가 특정 변수를 사용하려 할 때 이전에 동작한 스레드가 해당 변수를 사용하고 난 결과를 상식적으로 예측할 수 있는 상태에서 사용할 수 있다.

락은 상호 배제 뿐만 아니라 정상적인 메모리 가시성을 확보하기 위해서도 사용된다. 변경 가능하면서 여러 스레드가 공유해 사용하는 변수를 각 스레드에서 각자 최신의 정상적인 값으로 활용하려면 동일한 락을 사용해 모두 동기화 시켜야 한다.
공개 / 유출
특정 코드를 현재 코드의 스코프 범위를 넘어서도 사용할 수 있게 된다면 해당 변수/자원은 공개되었다고 한다. 이런 경우에는 반드시 해당 객체를 동기화 시켜야 한다. 만약 클래스 내부의 상태 변수를 외부에 공개해야 한다면 객체 캡슐화 작업이 물거품이 되거나 내부 데이터의 안정성을 해칠 수 있다.
객체가 안정적이지 않은 상태에서 공개하면 스레드 안정성에 문제가 생길 수 있다. 이처럼 의도적으로 공개시키지는 않았지만 외부에서 사용할 수 있게 공개된 경우를 유출 상태라고 한다.
- 인스턴스 자체를 통째로 반환하는 경우
- public static 과 같은 멤버 변수를 사용하는 경우
아래의 코드와 같이 작성하는 것은 금물이다.
public class ThisEscape {
public ThisEscape(EventSource source){
source.registerListner{
new EventListener() {
public void onEvent(Event e){
doSomething(e);
}
}
}
}
}
생성 메소드 안정성
생성 메소드를 실행하는 도중에는 this 변수가 외부에 유출되지 않게 해야 한다.
생성 메소드에서 this 변수를 유출시키는 가장 흔한 오류는 생성 메소드에서 스레드를 새로 만들어 시작시키는 일이다. 생성 메소드에서 또 다른 스레드를 만들어 내면 대부분의 경우에는 생성 메소드의 클래스와 새로운 스레드가 this 변수를 직접 공유하거나 자동으로 공유되기도 한다. 예를 들어 생성메소드에서 만든 스레드 의 클래스가 원래 클래스의 내부 클래스라면 자동으로 원래 클래스의 this 변수를 공유하는 상태가 된다.
새로 작성하는 클래스의 생성 메소드에서 이벤트 리스너를 등록하거나 새로운 스레드를 시작시키려면 아래의 코드와 같이 작성하는 편이 좋다. 생성 메소드에서 this 변수가 외부로 유출되지 않도록 팩토리 메서드를 사용하는 모습
public class SafeListener {
private final EventListener listener;
private SafeListener() {
listener = new EventListener() {
public void onEvent(Event e){
doSomething(e);
}
};
}
public static SafeListener newInstance(EventSource source){
SafeListener safe = new SafeListener();
source.registerListener(safe.listener);
return safe;
}
}
스레드 한정
변경 가능한 객체를 공유해 사용하는 경우에는 항상 동기화시켜야 한다. 만약 동기화 시키지 않아야 한다면, 기본적으로는 객체를 공유해 사용하지 않을 수 밖에 없다. 특정 객체를 단일 스레드에서만 활용한다고 확신할 수 있다면 해당 객체는 따로 동기화할 필요가 없다. 이처럼 객체를 사용하는 스레드를 한정하는 방법으로 스레드 안정성을 확보할 수 있다.
스레드 한정 - 주먹구구식
- 스택 한정
스택 한정 기법은 특정 객체를 로컬 변수를 통해서만 사용할 수 있는 특별한 경우의 스레드 한정 기법이라고 할 수 있다. 변수를 클래스 내부에 숨겨두면 변경상태를 관리하기가 쉬운데, 또한 클래스 내부에 숨겨둔 변수는 특정 스레드에 쉽게 한정시킬 수도 있다. 로컬 변수는 모두 암묵적으로 현재 실행 중인 스레드에 한정되어 있다고 볼 수 있다.
public int loadTheArk(Collection<Animal> candidates) {
SortedSet<Animal> animals;
int numPairs = 0;
Animal candidate = null;
// animals 변수는 메소드에 한정되어 있으며, 유출돼서는 안된다.
animals = new TreeSet<Animal> ( new SpeciesGenderComparator());
animals.addAll(candidates)
for ( Animal a : animals){
if(candidate == null || !candidate.isPotentialMate(a))
candidate = a;
else {
ark.load(new AnimalPair(candidate, a));
++numPairs;
candidate = null;
}
}
return numPairs;
}
객체형 변수가 스택 한정 상태를 유지할 수 있게 하려면 해당 객체에 대한 참조가 외부로 유출되지 않도록 개발자가 직접 주의를 기울여야 한다. 여기에서 만약 TreeSet 인스턴스에 대한 참조를 위부에 공개한다면 스택 한정 상태가 깨질수 밖에 없다.
ThreadLocal
스레드 로컬 변수는 변경 가능한 싱글턴이나 전역 변수 등을 기반으로 설계되어 있는 구조에서 변수가 임의로 공유되는 사항을 막기 위해 사용하는 경우가 많다. ThreadLocal 클래스에 get과 set 메소드가 있는데 호출하는 스레드 마다 다른 값을 사용할 수 있도록 관리해준다. 다시 말해 ThreadLocal 클래스의 get 메소드를 호출하면 현재 실행중인 스레드에서 최근에 set 메소드를 호출해 저장했던 값을 가져올 수 있다.
JDBC 연결은 스레드에 안전하지 않기 때문에 멀티 스레드 애플케이션에서 적절한 동기화 없이 연결 객체를 전역 변수로 만들어 사용하면 애플리케이션 역시 스레드에 안전하지 않다. 하지만 아래와 같이 JDBC 연결을 보관할 때 ThreadLocal을 사용하면 저마다의 연결 객체를 갖게된다.
private static ThreadLocal<Connection> connectionHolder = new ThreadLocal<Connection>() {
public Connection initialValue() {
return DriverManager.getConnection(DB_URL)
}
}
public static Connection getConnection(){
return connectionHolder.get();
}
만약 원래 단일 스레드에서 동작하던 기능을 멀티스레드 환경으로 구성해야할 때, 그 의미에 따라 다르지만 공유된 전역 변수를 ThreadLocal을 활용하도록 변경하면 스레드 안정성을 보장할 수 있다. 단일 쓰레드 애플리케이션에서 프로그램 전체를 대상으로 사용하던 캐시를 멀티 스레드 애플리케이션에서는 여러 개의 스레드별 캐시로 나눠 사용하는 편이 더 효과적일 것이다.
불변성
직접적으로 객체를 동기화하지 않고도 안전하게 사용할 수 있는 방법 가운데 마지막으로 알아볼 내용은 바로 불변 객체이다. 불변 객체는 맨 처음 생성되는 시점을 제외하고는 그 값이 전혀 바뀌지 않는 객체를 말한다. 다시 말해 불변 객체의 변하지 않는 값은 처음 만들어질 때 생성 메소드에서 설정되고, 상태를 바꿀수 없기 때문에 맨 처음에 설정된 값이 나중에도 바뀌지 않는다.
불변 객체는 아래의 조건을 만족해야 한다.
- 생성되고 난 이후에는 객체의 상태를 변경할 수 없다.
- 내부의 모든 변수는 final 로 설정돼야 한다.
- 적절한 방법으로 생성되어야 한다. this가 외부로 유출되지 않아야 한다.
@Immutable
public final class ThreeStooges{
private final Set<String> stooges = new HashSet<String>();
public ThreeStooges(){
stooges.add("Moe");
stooges.add("Larry");
stooges.add("Curly");
}
public boolean isStooges(String name){
return stooges.contains(name);
}
}
Final 변수
final을 지정한 변수의 값을 변경할 수 없다. 물론 변수가 가리키는 객체가 불변 객체가 아니라면 해당 객체에 들어있는 값은 변경할 수 있다. final 키워드를 적절하게 사용하면 초기화 안정성을 보장하기 때문에 별다른 동기화 작업 없이 불변 객체를 자유롭게 사용하고 공유할 수 있다.
@Immutable
class OneValueCache {
private final BigInteger lastNumber;
private final BigInteger[] lastFactors;
public OneValueCache(BigInteger i, BigInteger[] factors){
lastNumber = i;
lastFactors = Arrays.copyOf(factors, factors.length);
}
public BigInteger[] getFactors(BigInteger i) {
if ( lastNumber == null || !lastNumber.equals(i))
return null;
else
return Arrays.copyOf(lastFactors, lastFactors.leghth);
}
}
불변 객체의 요구조건
- 상태를 변경할 수 없어야 하고,
- 모든 필드의 값이 final로 선언되어야 하며,
- 적절한 방법으로 생성되어야 한다.
안전한 공개 방법의 특성
객체를 안전하게 공개하려면 해당 객체에 대한 참조와 객체 내부의 상태를 외부의 스레드에게 동시에 볼 수 있어야 한다. 올바르게 생성 메소드가 실행되고 난 개체는 아래와 같이 처리할 수 있다.
- 객체에 대한 참조를 static 메서드로 초기화 시킨다.
- 객체에 대한 참조를 volatile 변수 또는 AtomicReference 클래스에 보관한다.
- 객체에 대한 참조를 올바르게 생성된 클래스 내부의 final 변수에 보관한다.
- 락을 사용해 올바르게 막혀 있는 변수에 객체에 대한 참조를 보관한다.
HashTable, ConcurrentMap, synchronizedMap을 사용해 만든 Map 객체를 사용하면 그 안에 보관하고 있는 키와 값 모두를 어느 스레드에서라도 항상 안전하게 사용할 수 있다.
- 스레드 한정
- 읽기 전용 개체를 공유
- 스레드에 안전한 객체를 공유
- 동기화 방법 적용
객체구성
스레드 안전한 클래스 설계
클래스가 스레드 안정성을 확보하도록 설계하고자 할 때에는 아래를 고려해야한다.
- 객체의 상태를 보관하는 변수가 어떤 것인가?
- 객체의 상태를 보관하는 변수가 가질 수 있는 값이 어떤 종류, 어떤 범위에 해당하는가?
- 객체 내부의 값을 동시에 사용하고자 할 때, 그 과정을 관리할 수 잇는 정책
/*
primitive type을 사용할 경우 아래와 같이 객체의 상태를 완벽하기 동기화 처리 가능하다.
*/
@ThreadSafe
public final class Counter {
@GuardedBy("this") private long value = 0;
public synchronized long getValue() {
return value;
}
public synchronized long increment() {
if ( value == Long.MAX_VALUE )
throw new IllegalStateException("counter overflow");
return ++value;
}
}
동기화 요구 사항 정리
객체가 가질 수 있는 값의 범위와 변동 폭을 정확하게 인식하지 못한다면, 스레드 안정성을 완벽하게 확보할 수 없다. 클래스의 상태가 정상적이라는 여러 가지 졔약 조건이 있을 때 클래스의 상태를 정상적으로 유지하려면 여러 가지 추가적인 동기화 기법을 적용하거나 상태 변수를 클래스 내부에 적절히 숨겨야 한다.
상태 의존 연산
상태 소유권
인스턴스 한정
객체를 적절하게 캡슐화하는 것으로도 스레드 안정성을 확보할 수 있는데, 이런 경우 흔히 ‘한정’ 이라고 단순하게 부르기도 하는 ‘인스턴스 한정’ 기법을 활용하는 셈이다.
데이터를 객체 내부에 캡슐화해 숨겨두면 숨겨진 내용은 해당 객체의 메소드에서만 사용할 수 있기 때문에 숨겨진 데이터를 사용하고자 할 때는 항상 지정된 형태의 락이 적용되는지 쉽고 정확하게 파악할 수 있다.
@ThreadSafe
public class PersonSet {
@GuardedBy("this")
private final Set<Person> mySet = new HashSet<Person>();
public synchronized void addPerson(Person p) {
mySet.add(p);
}
public synchronized boolean containsPerson(Person p) {
return mySet.contains(p);
}
}
스레드의 안정성을 확보하는 방법으로 대부분 데코레이터(장식자) 패턴을 활용한다.
자바 모니터 패턴
자바 모니터 패턴을 따르는 객체는 변경 가능한 데이터를 모두 객체 내부에 숨긴 다음 객체의 암묵적인 락으로 데이터에 대한 동시 접근을 막는다. 자바 모니터 패턴은 단순한 관례에 불과하며 일정한 형태로 스레드 안전성을 확보할 수 있다면 어떤 형태의 락을 사용해도 무방하다.
public class PrivateLock {
private final Object myLock = new Object();
@GuardedBy("myLock") Widget Widget;
void someMethod() {
synchronized (myLock){
}
}
}
활동성
데드락
스레드 하나가 특정 락을 놓지 않고 계속해서 잡고 있으면 그 락을 확보해야하는 다른 스레드는 락이 풀리기를 영원히 기다리는 수밖에 없다. 스레드 A가 락 L을 확보한 상태에서 두 번째 락 M을 확보하려고 대기하고 있고, 그와 동시에 스레드 B는 락 M을 확보한 상태에서 락 L을 확보하려고 대기하고 있다면, 양쪽 스레드 A 와 B는 서로가 락을 풀기를 영원히 기다린다.
- Lock 순서에 의한 데드락
프로그램 내부의 모든 스레드에서 필요한 락을 모두 같은 순서로만 사용한다면 , 락 순서에 의한 데드락은 발생하지 않는다.
- 동적인 락 순서에 의한 Dead Lock 객체에 순서를 부여하여 이에 따라 락을 순서를 조절한다.
package studysample.java.Locking;
import sampleprogram.reactivesample.callrestapi.vo.ParameterVO;
import javax.naming.InsufficientResourcesException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Sample {
public static ExecutorService executorService = Executors.newFixedThreadPool(1000);
public static void main(String[] args) throws InsufficientResourcesException {
executorService.execute(new Runnable() {
@Override
public void run() {
try {
new Sample().tranferMoney(new Account(), new Account(), "100000");
} catch (InsufficientResourcesException e) {
e.printStackTrace();
}
}
});
}
private static final Object tieLock = new Object();
public void tranferMoney(final Account fromAcct, final Account toAcct, final String amount) throws InsufficientResourcesException {
class Helper {
public void tranfer() throws InsufficientResourcesException {
if (fromAcct.getBalance().compareTo(amount) < 0) {
throw new InsufficientResourcesException();
} else {
fromAcct.debit(amount);
toAcct.credit(amount);
}
}
}
int fromHash = System.identityHashCode(fromAcct);
int toHash = System.identityHashCode(toAcct);
if(fromHash < toHash) {
synchronized (fromAcct){
synchronized (toAcct){
new Helper().tranfer();
}
}
}else if(fromHash > toHash){
synchronized (toAcct){
synchronized (fromAcct){
new Helper().tranfer();
}
}
}else {
synchronized (tieLock){
synchronized (fromAcct){
synchronized (toAcct){
new Helper().tranfer();
}
}
}
}
}
}
class Account {
public String getBalance(){
return "5000";
}
public void debit(String amount){
}
public void credit(String amount){
}
}
class DollarAmount{
}
- 객체간의 데드락
락을 확보한 상태에서 에일리언 메소드를 호출한다면 가용선에 문제가 생길 수 있다. 에일리언 메소드 내부에서 다른 락을 확보하려고 하거나, 아니면 예상하지 못한 만큼 오랜 시간 동안 계속해서 실행된다면 호출하기전에 확보했던 락이 필요한 다른 스레드가 계속해서 대기해야하는 경우도 생길 수 있다.
- 오픈 호출 (내용 재정리 필요)
프로그램을 작성할 때, 최대한 오픈 호출 방법을 사용하도록 한다. 내부의 모든 부분에서 오픈 호출을 사용하는 프로그램은 락을 확보한 상태로 메소드를 호출하곤 하는 프로그램보다 데드락 문제를 찾아내기 위한 분석 작업을 훨씬 간편하게 해준다.
- 리소스 데드락
스레드가 서로 상대방이 이미 확보하고 앞으로 놓지 않을 락을 기다리느라 서로 데드락에 빠질 수 있는 것 처럼, 필요한 자원을 사용하기 위해서 대기하는 과정에도 데드락이 발생할 수 있다.
데드락 방지 및 원인 추적
한 번에 하나 이상의 락을 사용하지 않는 프로그램은 락의 순서에 의한 데드락이 발생하지 않는다. 가능하다면 한 번에 하나 이상의 락을 사용하지 않도록 프로그램을 만들어보는 것도 좋다.
- 락의 시간제한
데드락 상태를 검추하고 데드락에서 복구하는 또 다른 방법으로는 synchronized 등의 구문으로 암묵적인 락을 사용하는 대신 Lock 클래스의 메소드 가운데 시간을 제한 할 수 있는 tryLock 메소드를 사용하는 방법이 있다.
- 스레드 덤프를 활용한 데드락 분석 ( 재정리 필요 )
- 소모 (재정리 필요)
- 형편없는 응답성 ( 재정리 필요 )
- 라이브 락 ( 재정리 필요)
성능 및 확장성
확장성 : CPU, 메모리, 디스크, I/O 처리 장치 등의 추가적인 장비를 사용해 처리량이나 용량을 얼마나 쉽게 키울 수 있는지를 말한다.

서버 애플리케이션을 만들 때는 성능의 여러가지 측면 가운데 ‘얼마나 빠르게’ 라는 측면보다 ‘얼마나 많이’라는 측면, 즉 확장성과 처리량과 용량이라는 세 개의 측면이 훨씬 중요하게 생각하는 경우가 많다.
성능 트레이드 오프 측정
‘퀵소트’ 알고리즘은 대량의 자료를 정렬할 때 효율이 높지만, 자료의 양이 많지 않을 때에는 훨씬 기초적인 ‘버블 소트’ 알고리즘이 더 효율적이기도 하다.
최적화 기법을 너무 이른 시점에 적용하지 말아야 한다. 일단 제대로 동작하게 만들고 난 다음에 빠르게 동작하도록 최적화해야 하며, 예상한 것보다 심각하게 성능이 떨어지는 경우에만 최적화 기법을 적용하는 것으로도 충분하다.
- ‘빠르다’ 단어가 무엇을 의미하는가?
- 어떤 조건을 갖춰야 이 방법이 실제로 ‘빠르게’ 동작할 것인가? 부하가 적을때? 아니면 부하가 걸릴 때? 데이터가 많을 때? 아니면 적을 때? 이런 질문에 대답할 명확한 수치를 보여줄 수 있는가?
- 위의 조건에 해당하는 경우가 얼마나 발생하는가? 이 질문에 대한 명확한 수치를 보여줄 수 있는가?
- 조건이 달라지는 다른 상황에서도 같은 코드를 사용할 수 있는가?
- 이 방법으로 성능을 개선하고자 할때, 숨겨진 비용, 즉 개발 비용이나 유지보수 비용이 증갛는 부분이 어느 정도인지? 과연 그런 비용을 감수하면서 까지 성능 개선 작업을 해야하는가?
추측하지 말고, 실제로 측정해보라.

동기화 클래스 구현
상태 종속성 관리
상태 종속적인 작업의 동기화 구조
void blockingAction() throws InterruptedException {
상태 변수에 대한 락 확보
while ( 선행 조건이 만족하지 않음 ) {
확보했던 락을 풀어줌
선행 조건이 만족할만한 시간만큼 대기
인터럽트에 걸리거나 타임아웃이 걸리면 멈춤
락을 다시 확보
}
작업 실행
락 해제
}
프로듀서 - 컨슈머 패턴으로 구현된 애플리케이션에서는 ArrayBlockingQueue와 같이 크기가 제한된 큐를 많이 사용한다. 크기가 제한된 큐는 put 과 take 메소드를 제공하며, put 과 take 메소드에는 다음과 같은 선행조건이 있다. 버퍼 내부가 비어 있다면 값을 take 할 수 없고, 버퍼가 가득 차 있다면 값을 put 할 수 없다. 상태 종속적인 메소드에서 선행조건과 관련된 오류가 발생하면 예외를 발생시키거나 오류 값을 리턴하기도 하고, 아니면 선행 조건이 원하는 상태에 도달할 때 까지 대기하기도 한다.
JDK 라이브러리의 Queue 클래스는 두 가지 방법을 모두 사용할 수 있도록 하고 있다. 큐가 비어 있는 경우에 poll 메소드는 null을 리턴하고 remove 메소드는 예외를 던진다. 하지만 프로듀서-컨슈머 패턴에서는 Queue를 사용하는 것이 그다시 적절하지는 않다. 프로듀서 컨슈머 패턴에는 BlockingQueue와 같이 작업을 계속 진행하기에 적절한 상태가 아니라면 계속해서 대기하는 클래스가 더 적당한 선택이다.
폴링하고 대기하는 반복 작업을 통해 블로킹 연산을 구현하는 일은 상당히 고생스러운 일이다. 조건이 맞지 않으면 스레드를 멈추지만, 만약 원하는 조건에 도달하면 그 즉시 스레드를 다시 실행시킬 수 있는 방법이 있다면 좋지 않을 까? 이를 담당하는 구조가 바로 조건 큐이다.
조건큐의 활용
조건 큐는 여러 스레드를 한 덩어리로 묶어 특정 조건이 만족할 때까지 한꺼번에 대기할 수 있는 방법을 제공하기 때문에 ‘조건 큐’ 라는 이름으로 불린다. 데이터 값으로 일반적으로 객체를 담아두는 보통의 큐와 달리 조건 큐에는 특정 조건이 만족할 때까지 대기해야 하는 스레드가 값으로 들어간다.
자바 언어에서 사용하는 모든 객체를 락으로 활용할 수 있는 것 처럼 모든 객체는 스스로를 조건 큐를 사용할 수 있으며, 모든 객체가 갖고 있는 wait, notify, notifyall 메소드는 조건 큐의 암묵적인 API라고 봐도 좋다.
X 라는 객체의 조건 큐 API를 호출하고자 하면 반드시 객체 X의 암묵적인 락을 확보하고 있어야만 한다.
Object.wait 메소드는 현재 확보하고 있는 락을 자동으로 해제하면서 운영 체제에게 현재 스레드를 멈춰달라고 요청하고, 따라서 다른 스레드가 락을 확보해 객체 내부의 상태를 변경할 수 있도록 해준다. 대기 상태에서 깨어나는 순간에는 해제했던 락을 다시 확보한다.
@ThreadSafe
public class BoundedBuffer<V> extends BaseBoundedBuffer<V> {
// 조건 서술어 : not-full ( !isFull() )
// 조건 서술어 : not-empty ( !isEmpty() )
public BuoundBuffer(int size) { super(size); }
// 만족할 때까지 : not-full
public synchronized void put (V v) throws InterruptedException {
while ( isFull() )
wait();
doput(v);
notifyAll();
}
// 만족할 때까지 대기 : not-empty
public synchronized V take() throws InterruptedException {
while ( isEmpty() )
wait();
V v = doTake();
notifyAll();
return v;
}
}
조건 큐 활용
- 조건 서술어
조건 큐를 올바로 사용하기 위한 핵심적인 요소는 바로 해당 객체가 대기하게 될 조건 서술어를 명확하게 구분해내는 일이다. wait, notify를 사용함에 있어서 가장 많은 혼란을 줄 수 있는 요소가 바로 조건 서술어인데, JDK 라이브러리 API 에도 전혀 언급되지 않고, 조건 서술어를 올바르게 사용하는데 꼭 필요한 내용이 자바 언어 명세나 JVM 구현 메뉴얼 어디에도 소개돼 있지 않기 때문이다. 조건 서술어는 애초에 특정 기능이 상태 종속적이 되도록 만드는 선행 조건을 의미한다. 크기가 제한된 버퍼로 예를 들면 take 메소드는 버퍼에 값이 들어 있는 경우에만 작업을 진행할 수 있고, 버퍼가 비어 있다면 대기해야 한다. 그러면 take 메소드의 입장에서는 작업을 진행하기 전에 확인해야만 하는 “버퍼에 값이 있어야 한다”는 것이 조건 서술어입니다. 조건 부 대기와 관련된 락과 wait 메소드가 조건 서술어는 중요한 삼각관계를 유지하고 있다. 조건 서술어는 상태 변수를 기반으로 하고, 상태 변수는 락으로 동기화 돼 있으니 조건 서술어를 만족하는지 확인하려면 반드시 락을 확보해야만 한다. 또한 락 객체와 조건 큐는 반드시 동일한 객체여야만 한다.
void stateDependentMethod() throws InterruptedException {
// 조건 서술어는 반드시 락으로 동기화된 이후에 확인해야 한다.
synchronized(lock) {
while ( !ConditionPredicate() )
lock.wait();
// 객체가 원하는 상태가 맞춰졌다.
}
}
- 조건부 wait 메소드를 사용할 때는
- 항상 조건 서술어를 명시해야한다.
- wait 메소드를 호출하기 전에 조건 서술어를 확인하고, wait에서 리턴된 이후에도 조건 서술어를 확인해야 한다.
- wait 메소드는 항상 반복문 내부에서 호출해야 한다.
- 조건 서술어를 확인하는 데 관련된 모든 상태 변수는 해당 조건 큐의 락에 의해 동기화 돼 있어야 한다.
- wait, notify, notifyAll 메소드를 호출할 때는 조건 큐에 해당하는 락을 확보하고 있어야 한다.
- 조건 서술어를 확인한 이후 실제로 작업을 실행해 작업이 끝날 때까지 락를 해제해서는 안 된다.
-
알림
- 특정 조건을 놓고 wait 메소드를 호출해 대기 상태에 들어간다면, 해당 조건을 만족하게 된 이후에 반드시 알림 메소드를 사용해 대기 상태에서 빠져나오도록 해야 한다.
-
여러 개의 스레드가 하나의 조건 큐를 놓고 대기 상태에 들어갈 수 있는데, 대기 상태에 들어간 조건이 서로 다를 수 있기 때문에 notifyAll 대신 notify 메소드를 사용해 대기 상태를 풀어주는 방법은 위험성이 높다. 단 한번만 알림 메시지를 전달하게 되면 앞서 소개했던 ‘놓친신호’와 유사한 문제가 생길 가능성이 높다.
- notifyAll 대신 notify 메소드를 사용하려면 다음과 같은 조건에 해당하는 경우에만 사용하는 것이 좋다.
- 단일 조건에 따른 대기 상태에서 깨우는 경우
- 해당 하는 조건 큐에 단 하나의 조건만 사용하고 있는 경우이고, 따라서 각 스레드는 wait 메소드에서 리턴될 때 동일한 방법으로 실행된다.
- 한 반에 하나씩 처리하는 경우
- 조건 변수에 대한 알림 메소드를 호출하면 하나의 스레드만 실행시킬 수 있는 경우
같이 알아두기
Register는 Flip Flop의 집합이며, 이 Flip Flop이라는 것은 각각 1bit의 정보를 저장할 수 있는 것들을 의미한다. 결국 n-bit registrer라는 것은 n bit의 정보를 저장할 수 잇는 것들을 의미한다. 결국 n-bit Register 라는 것은 n bit의 정보를 저장할 수 있는 결국 n개의 Flip Flop으로 이루어진 Flip Flop의 Group을 말하는 것이다. 이런 의미에서 Register라는 것은 최소 1 bit 단위로 정보를 저장 또는 수정할 수 있다.
- 뮤텍스
뮤텍스란 Mutual Exclusion으로 우리말로 해석하면 ‘상호 배제’ 라고 한다. Critical Section을 가진 Thread 들의 running time 이 서로 겹치지 않게 , 각각 단독으로 실행되게 하는 기술 이다. 만약 어느 Thread에서 Critical Section 을 실행하고 있으면 다른 Thread 들이 그 Critical Section 에 접근할 수 없고 앞의 Thread가 Critical Section을 벗어나기를 기다려야 한다. Critical Section : 프로그램 상에서 동시에 실행될 경우 문제를 일으킬 수 있는 부분
- 스테일 데이터 ( stale data )
컴퓨터 처리에서, 만약 한 프로세서가 피 연산자의 값을 변경하고 그리고 이어서 그 피연산자를 불러왔을 때, 피연산자의 값이 새로운 값이 아닌 변경되기 이전의 값을 가지고 왔다면, 이 때 그것을 스테일 데이터라고 부른다.
멀티스레드 프로그래밍의 고찰
멀티스레드 프로그램의 성능은 스레드의 “동시성 향상 효과”와 “Context Switching 비용”의 Trade Off에 의해 결정된다고 말할 수 있습니다.
가장 적절한 스레드의 수는 CPU의 수와 스레드가 수행하는 작업의 성격을 함께 고려하여 결정되는데 일반적으로는 연산 위조의 작업의 경우, CPU당 2~3개 I/O 위조의 작업의 경우 CPU당 5개 내외의 적절한 스레드의 수로 가이드하며, 스레드풀을 생성할 때 워크 스레드의 수를 한정하는 방식으로 사용한다.