Hadoop 이란?
포기하지 않기.
The Google File System(GFS)을 기반으로 하여 하둡 분산 파일 시스템(HDFS)가 개발되었음.
-
기본 구조
- HDFS는 Master-Slave 구조로 되어 있다. 여기에서 가장 중요한 부분은 Master의 안정성을 보장할 수 있는 구조가 되어야 한다.
- Master-Slave 구조라는 것은 Slave 가 n 대로 확장해 나가는 구조라고 생각하면 된다.
-
구글 플랫폼의 기본 요건
- 한대의 고가 장비보다 여러 대의 저가 장비가 낫다.
- 데이터는 분산 저장한다.
- 시스템은 언제든 죽을 수 있다.
- 시스템 확장이 쉬워야 한다.
-
하둡 특성
- 수천대 이상의 리눅스 기반 범용 서버들을 하나의 클러스터로 사용
- 마스터 - 슬레이브 구조
- 파일은 블록(block) 단위로 저장
- 블록 데이터의 복제본 유지로 인한 신뢰성 보장 ( 기본 3개의 복제본 )
- 높은 내 고장성 ( Fault Tolerance )
- 데이터 처리의 지역성 보장
-
하둡 Cluster 네트워크 / 데몬 구성
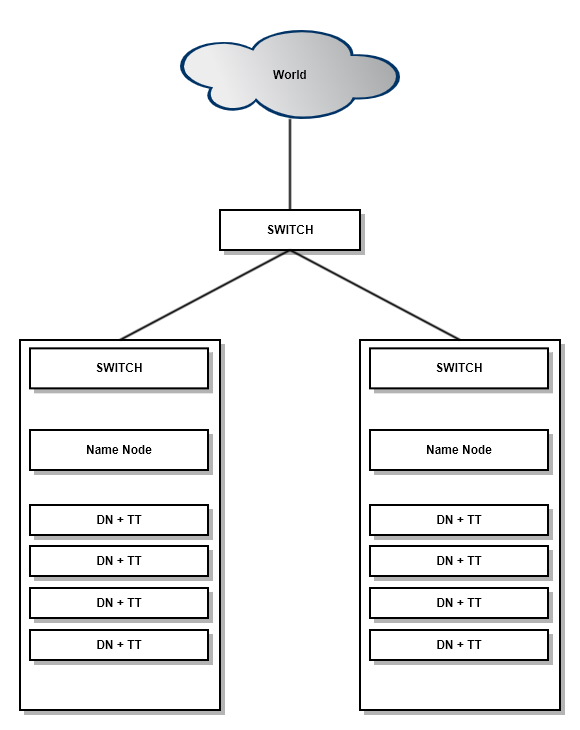
하둡의 경우, 여러대의 구성은 큰 의미가 없고 최소 몇십대 이상의 구성으로 구축하여 사용 가능함. 여러대의 서버를 하나의 클러스터로 구성되게 되어 있음.
- DN : Data Node
- TT : Task Tracker
하둡에서 블록이란?
- 하나의 파일을 여러 개의 Block으로 저장
- 설정에 의해 하나의 Block은 64MB 또는 128MB 등의 큰 크기로 나누어 저장
- 블록 크키가 128MB 보다 적은 경우는 실제 크기 만큼만 용량을 차지함
하둡에서 블록(Block) 하나의 크기가 큰 이유는?
- HDFS의 블록은 128MB와 같이 매우 큰 단위
- 블록이 큰 이유는 탐색 비용을 최소화 할 수 있기 때문
- 블록이 크면 하드 디스크에서 블록의 시작점을 탐색하는 데 걸리는 시간을 줄일 수 있고, 네트워크를 통해 데이터를 전송하는데 더 많은 시간을 할당이 가능함.
하둡은 자체적으로 들어온 데이터를 128MB 기준으로 분리하여 저장 처리한다. 마스터 서버에는 데이터를 저장하지 않음.
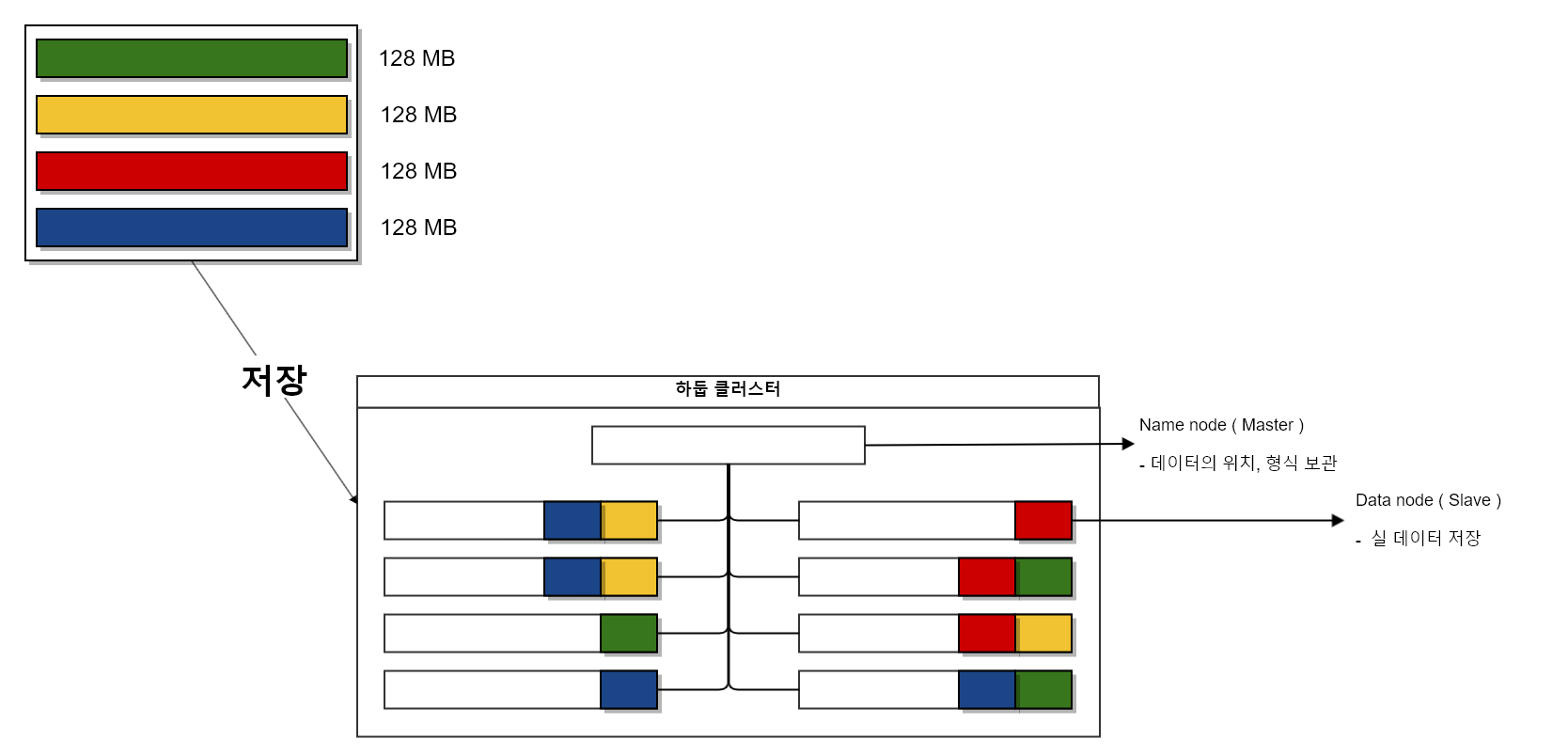
데이터가 각각 분산 저장되는 구조로 수정되어 있음.
- 데이터를 조각 내어 서버 내 분산 저장
- 데이터를 복사하여 여러 개를 저장
또한 Slave의 데이터 노드가 Master에게 일정 간격으로 heartbeat를 보내게 되어 있음. 이를 이용해서 하둡 클러스터 내에서 한 대의 서버에 장애가 발생하였을 경우, heartbeat에 의해서 나머지 서버들에 고장난 한대의 서버에의 데이터 노드를 다시 재분산 저장함. 서버 장애에 대한 복구 시간 동안에 데이터 유실이 발생할 수 있는 경우는 데이터 센터의 천재지변등이 아니면 발생 할 수 없음.
하둡 클러스터의 규모가 커질 경우, Naem Node의 서버 스펙(메모리)가 좋아야할 필요가 있음 - 스펙이 좋은 것으로 구성하는 것이 좋음
- 마스터 서버의 장애에 대한 대응책
- 마스터 서버의 장애를 대응해서 나온 버전이 Hadoop 2.0 이상 부터임
- 마스터 서버의 이중화 : hadoop 2.0
블록의 지역성(Locality)
- 네트워크를 이용한 데이터 전송 시간 감소
- 대용량 데이터 확인을 위한 디스크 탐색 시간 감소
- 적절한 단위의 블록 크기를 이용한 CPU 처리 시간 증가
실제가 데이터가 있는 곳에 가서 연산을 먼저 수행하는 것이 Locality의 기본 특성임.
참고 : 클라우드 스토리지를 이용하는 경우, HDFS를 사용하는 것보다 성능 저하가 있을 수 있음
블록 캐싱
- 데이터 노드에 저장된 데이터 중 자주 읽는 블록은 블록 캐시라는 데이터 노드의 메모리에 명시적으로 캐싱할 수 있음
- 파일 단위로 캐싱 할 수도 있어서 조인에 사용되는 데이터들을 등록하여 읽기 성능을 높일 수 있음
네임노드(NameNode)의 역할
- 전체 HDFS에 대한 Name Space 관리
- DateNode로 부터 Block 리포트를 받음
- Data에 대한 Replication 유지를 위한 커맨더 역할 수행
- 파일 시스템 이미지 파일 관리 ( fsImage ) : fsImage가 상당히 중요함. - Sanpshot임.
- 파일 시스템에 대한 Edit Log 관리
보조 네임 노드(SNN)
- 네임노드(NN)와 보조 네임노드(SNN)
- Active / StandBy 구조 아님
- fsimage 와 edits 파일을 주기적으로 병합
- 체크 포인트
- 1시간 주기로 실행
- edit 로그가 일정 사이즈 이상이면 실행
- 이슈사항
- 네임노드가 SPOF
- 보조 네임노드의 장애 상황 감지 툴 없음
데이터 노드(Datanode) 역할
- DataNode는 물리적으로 로컬 파일 시스템에 HDFS 데이터를 저장.
- DataNode는 HDFS에 대한 지식이 없음
- 일반적으로 레이드 구성을 하지 않음 ( JBOD 구성 )
- 블록 리포트 : NameNode가 시작 될 때, 그리고 ( 주기적으로 ) 로컬 파일 시스템에 있는 모든 HDFS 블록들을 검사 후 정상적인 블록의 목록을 만들어 NameNode에 전송
데이터 노드 블록 스캐너
- Data Node는 블록 리포트 : Name Node가 시작 될 때, 그리고 (추가적으로) 로컬 파일 시스템에 있는 모든 HDFS 블록들을 검사 후 정상적인 블록의 목록을 만들어 NameNode에 전송
HDFS 쓰기 연산 처리 메커니즘
- 데이터 복제시 클라이언트가 네임노드로 부터 데이터 노드 리스트를 전달 받음
- 파이프라인 형대로 데이터를 복사 ( 4kb 단위 )
- 네트워크 트래픽은 클라이언트와 데이터 노드 간에만 발생
참고해야할 개념
- ETL(Extraction Transforamtion Load / 추출, 변형, 적재)
- ETL은 데이터의 이동 및 변환 절차와 관련된 업계 표준 용어
- 다양한 데이터 원천으로부터 데이터를 추출 및 변환하여 운영 데이터 스토어(ODS), 데이터 웨어하우스(DW), 데이터마트(DW) 등에 데이터를 적재하는 작업의 핵심 구성요소
- ETL은 대용량 데이터에 대한 일괄(Batch)작업(일괄작업 = 실시간의 반대개념)을 통해 정형 데이터를 통합
- 그렇다면, 정형 데이터의 실시간 혹은 근접 실시간 처리와 통합에 관한 기술은? → CDC와 EAI
- 패리티 비트
패리티 비트(Parity bit)는 정보의 전달 과정에서 오류가 생겼는지를 검사하기 위해 추가된 비트이다. 문자열 내 1비트의 모든 숫자가 짝수 또는 홀수인지를 보증하기 위해 전송하고자 하는 데이터의 각 문자에 1 비트를 더하여 전송하는 방법으로 2가지 종류의 패리티 비트(홀수, 짝수)가 있다. 패리티 비트는 오류 검출 부호에서 가장 간단한 형태로 쓰인다.
짝수(even) 패리티는 전체 비트에서 1의 개수가 짝수가 되도록 패리티 비트를 정하는 것인데, 이를테면 데이터 비트에서 1의 개수가 홀수이면 패리티 비트를 1로 정한다. 홀수(odd) 패리티는 전체 비트에서 1의 개수가 홀수가 되도록 패리티 비트를 정하는 방법이다. 7비트의 0010110라는 데이터에서 짝수 패리티가 되게 하기 위해서는 1의 패리티 비트를 붙여 10010110로 한다. 또 같은 데이터에 대해 홀수 패리티 비트가 되게 하려면 0의 패리티 비트를 붙인다. 이렇게 패리티 비트를 정하여 데이터를 보내면 받는 쪽에서는 수신된 데이터의 전체 비트를 계산하여 패리티 비트를 다시 계산함으로써 데이터 오류 발생 여부를 알 수 있다. 그러나 패리티 비트는 오류 발생 여부만 알 수 있지 오류를 수정할 수는 없다
- JBOD
JBOD는 RAID용으로 구성되어 있지 않은 컴퓨터 하드디스크를 다소 낮추어 부르는 용어이며, 이를 가리키는 원래의 용어는 “spanning”이다.
RAID 시스템은 동일한 데이터를 여러 개의 디스크에 중복 저장하면서도, 운영체계에는 하나의 단일 디스크로 인식시킴으로써, 내고장성의 증가와 데이터 접근 효율성을 높여준다. JBOD도 역시 여러 개의 디스크를 하나의 디스크로 보이게 해 주긴 하지만, 이는 여러 개의 디스크를 논리적인 하나의 커다란 디스크로 결합해주는 것일 뿐, 각각의 디스크를 독립적으로 사용하는 것에 비해 어떠한 장점도 제공하지 않으며, RAID에서 기대할 수 있는 내고장성이나 성능 향상 등의 이점 역시 제공하지 않는다.
https://www.youtube.com/watch?v=pixlGPc4vbA&list=PL9mhQYIlKEheGLT1V_PEby_I9pOXr1o3r&index=3 [하둡 분산 파일 시스템의 이해(1) - T 아카데미] https://specialscene.tistory.com/31 https://ko.wikipedia.org/wiki/%ED%8C%A8%EB%A6%AC%ED%8B%B0_%EB%B9%84%ED%8A%B8